
こんにちは!今回は、AWSを使ってリアルタイムにデータを収集・保存・分析するシステムを、初心者の方でも理解できるように丁寧に解説します。
この記事では、以下のような構成を作ります:
🔧 システム全体構成図
[送信スクリプト] → [Kinesis Data Stream] → [Lambda関数] → [S3] → [Athenaでクエリ分析]これらの構成を、AWS CloudFormation(以下CFn)という仕組みを使って、一括で構築できるようにしていきます。
✅ 用語の解説
AWS Lambda:ログ生成・取得や前処理を担うサーバレス関数。イベントを受け取るとデータを整形して Kinesis Data Streams に送信します。
Amazon Kinesis Data Streams:高スループットなストリーミングデータサービス。Lambda から送られてきたログレコードをシャードに蓄積し、Firehose のソースとして利用します。
Amazon Kinesis Data Firehose:ストリーミングデータを取り込み、指定したストレージ(ここでは S3)に配信するサービス。Kinesis Stream からのデータを受け取り、バッファリングしつつファイルに書き出しますまた Firehose ではデータ変換機能があり、JSON を Parquet/ORC に変換して効率を高めることも可能です
Amazon S3:オブジェクトストレージ。Firehose により出力されたログデータを格納しますS3 上では日付やサービス名などでプレフィックス(パーティション)分けすることで、Athena クエリの性能向上やコスト削減が期待できます。
AWS Glue:サーバレスなデータ準備・カタログサービス。Glue クローラーを使い S3 上の新規データを走査してスキーマを自動推定し、Glue Data Catalog にテーブル定義を作成しますこうして作られたテーブルを Athena が参照してクエリを実行できます。
Amazon Athena:サーバレスな対話型クエリサービス。Glue Data Catalog 上のテーブルを使い、S3 上のデータに対して標準的なSQLで分析します。CloudFormation では Athena のワークグループや NamedQuery を定義しておくことも可能です
🧱 CloudFormationテンプレート
以下は、Kinesis + Lambda + S3 を構成するCloudFormationテンプレートの一例です。
AWSTemplateFormatVersion: '2010-09-09'
Description: >
Kinesis + Firehose + S3 + Glue + Lambda 構成
- Lambda で Kinesis にサンプルデータ送信
- Firehose 経由で GZIP 圧縮し S3 保存
- Glue で Crawler 実行 → Athena クエリ可能
Resources:
# S3バケット(GZIPログ保存用)
MyS3Bucket:
Type: AWS::S3::Bucket
Properties:
VersioningConfiguration:
Status: Enabled
# Kinesisストリーム(1シャード)
KinesisStream:
Type: AWS::Kinesis::Stream
Properties:
ShardCount: 1
# Firehose用IAMロール
FirehoseRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service: firehose.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: FirehosePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:PutObject
- s3:PutObjectAcl
- s3:GetBucketLocation
Resource:
- !GetAtt MyS3Bucket.Arn
- !Sub "${MyS3Bucket.Arn}/*"
- Effect: Allow
Action:
- kinesis:DescribeStream
- kinesis:GetShardIterator
- kinesis:GetRecords
Resource: !GetAtt KinesisStream.Arn
# Firehose Delivery Stream
FirehoseDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt KinesisStream.Arn
RoleARN: !GetAtt FirehoseRole.Arn
ExtendedS3DestinationConfiguration:
BucketARN: !GetAtt MyS3Bucket.Arn
RoleARN: !GetAtt FirehoseRole.Arn
Prefix: logs/web_access/
CompressionFormat: GZIP
BufferingHints:
IntervalInSeconds: 60
SizeInMBs: 5
# Lambda実行ロール
LambdaExecutionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: LambdaKinesisPolicy
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- kinesis:PutRecord
- kinesis:PutRecords
Resource: !GetAtt KinesisStream.Arn
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: "*"
# Lambda関数(サンプルデータをKinesisへ送信)
SampleDataLambda:
Type: AWS::Lambda::Function
Properties:
Handler: index.lambda_handler
Runtime: python3.12
Role: !GetAtt LambdaExecutionRole.Arn
Timeout: 10
Code:
ZipFile: |
import boto3
import json
import os
import random
import time
def lambda_handler(event, context):
kinesis = boto3.client('kinesis')
data = {
"ip": f"192.168.1.{random.randint(1, 254)}",
"timestamp": int(time.time()),
"user_agent": "Mozilla/5.0"
}
kinesis.put_record(
StreamName=os.environ["KINESIS_STREAM_NAME"],
Data=json.dumps(data),
PartitionKey="partitionKey"
)
return {"statusCode": 200, "body": "Data sent"}
Environment:
Variables:
KINESIS_STREAM_NAME: !Ref KinesisStream
# EventBridgeルール(Lambdaを1分ごとに実行)
SampleDataScheduleRule:
Type: AWS::Events::Rule
Properties:
ScheduleExpression: rate(1 minute)
Targets:
- Arn: !GetAtt SampleDataLambda.Arn
Id: "TargetLambdaFunction"
# Lambda に EventBridge 実行権限付与
LambdaInvokePermission:
Type: AWS::Lambda::Permission
Properties:
FunctionName: !Ref SampleDataLambda
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt SampleDataScheduleRule.Arn
# Glueのロール(S3 + Glue用)
GlueServiceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service: glue.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: GlueAccess
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
- s3:ListBucket
Resource:
- !GetAtt MyS3Bucket.Arn
- !Sub "${MyS3Bucket.Arn}/*"
- Effect: Allow
Action:
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
Resource: "*"
- Effect: Allow
Action:
- glue:*
Resource: "*"
# Glue Database
GlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: web_access_db
# Glue Crawler
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: web-access-crawler
Role: !GetAtt GlueServiceRole.Arn
DatabaseName: !Ref GlueDatabase
Targets:
S3Targets:
- Path: !Sub "s3://${MyS3Bucket}/logs/web_access/"
SchemaChangePolicy:
UpdateBehavior: UPDATE_IN_DATABASE
DeleteBehavior: LOG
# Glue Trigger(毎時 Crawler 実行)
GlueCrawlerScheduleTrigger:
Type: AWS::Glue::Trigger
Properties:
Name: web-access-trigger
Type: SCHEDULED
Schedule: "cron(0 * * * ? *)" # 毎時0分
Actions:
- CrawlerName: !Ref GlueCrawler
StartOnCreation: true
Outputs:
S3BucketName:
Description: ログ保存用S3バケット名
Value: !Ref MyS3Bucket
KinesisStreamName:
Description: Kinesis Stream名
Value: !Ref KinesisStream
FirehoseName:
Description: Firehose Delivery Stream名
Value: !Ref FirehoseDeliveryStream
GlueDatabaseName:
Description: Glue データベース名
Value: !Ref GlueDatabase
AthenaQueryExample:
Description: Athena で実行可能なクエリ例
Value: |
SELECT * FROM "web_access_db"."logs_web_access" LIMIT 10;
各サービスの説明と連携
AWS Lambda
AWS Lambda はイベント駆動型のサーバレス関数で、ここではログを受け取って処理し、Kinesis Data Streams に送信する役割を担います。Lambda 関数内では AWS SDK (boto3) を使い、kinesis.put_record でストリームにデータを送信できます。例えば、JSON化したログメッセージを put_record の Data パラメータに渡し、PartitionKey でシャード分散を指定します。CloudFormation では AWS::Lambda::Function リソースで関数を定義し、IAM ロールに対して Kinesis への書き込み権限(kinesis:PutRecord)を付与します。
Amazon Kinesis Data Streams
Kinesis Data Streams はスケーラブルなストリーミングデータサービスで、ストリーム名・シャード数を指定して作成します。Lambda 関数から送られた各レコードは JSON 文字列などで put_record メソッドを用いてストリームに書き込まれます.
これにより、データは指定したシャードに蓄積され、後続処理で並列に取り出すことが可能です。CloudFormation では AWS::Kinesis::Stream リソースを使い、ShardCount や保持期間などを設定します。Kinesis ストリームにデータが入ると、次段の Firehose がこのストリームをソース(DeliveryStreamType: KinesisStreamAsSource)として読み込みます
Amazon Kinesis Data Firehose
Kinesis Data Firehose(配信ストリーム)は、ストリーミングデータを自動的に指定先へ書き出すサービスです。CloudFormation では AWS::KinesisFirehose::DeliveryStream で定義し、KinesisStreamSourceConfiguration にストリームの ARN を指定して Kinesis ストリームをソースとします。Firehose は受信したレコードを一定量または一定時間ごとにまとめてバッファリングし、ExtendedS3DestinationConfiguration で指定した S3 バケットにファイルとして出力します。Firehose にはデータ変換機能もあり、JSONデータを列指向フォーマット(Parquet/ORC)に変換して Athena クエリを高速化できます。例として、JSON レコードを Parquet に変換するよう設定すれば、保存容量とクエリコストを削減できます。Firehose の S3 出力設定では、バッファサイズや圧縮方式、ファイル名のプレフィックスなどを細かく指定します。
Amazon S3
Amazon S3 は長期的なオブジェクトストレージであり、Firehose から受け取ったログデータを蓄積する役割を担います。CloudFormation では AWS::S3::Bucket でバケットを作成し、Firehose の出力先にその ARN を指定します。S3 では、Firehose が吐き出すJSONファイルやParquetファイルを保存します。一般にログ分析では、/year=YYYY/month=MM/day=DD/ のように日付別のプレフィックスを付けることで、Athena のクエリ効率を上げることができます。また、Firehose の「S3 バックアップ」モードを有効化しておくと、配信失敗したレコードを別バケットに保存するなどの冗長化も可能です。
AWS Glue(データカタログとクローラー)
AWS Glue はサーバレスの ETL およびデータカタログサービスです。ここでは主に Glue データカタログを利用し、S3 に保存されたログのスキーマを管理します。CloudFormation では AWS::Glue::Database でデータベースを作成し、AWS::Glue::Crawler でクローラーを設定します。クローラーの Targets.S3Targets.Path にログ保存先の S3 パスを指定し、実行すると S3 上のファイルを走査してテーブルとカラムを自動生成します。また、TablePrefix でテーブル名のプレフィックスを設定し、SchemaChangePolicy で列追加時の動作(既存テーブルへの更新許可など)を指定できます。例えば以下のように設定します:
# Glue Crawler 定義例 (CloudFormation YAML)
GlueCrawler:
Type: AWS::Glue::Crawler
Properties:
Name: !Sub Crawler-${AWS::AccountId}-${AWS::Region}
Role: <GlueCrawler実行ロールARN>
DatabaseName: !Ref GlueDatabase
Targets:
S3Targets:
- Path: !Ref DataS3BucketPath # ログデータのS3パス
TablePrefix: 'my_logs_'
SchemaChangePolicy:
UpdateBehavior: UPDATE_IN_DATABASE
DeleteBehavior: LOG
この例では、S3 の指定パスをターゲットにし、my_logs_ というプレフィックスでテーブルを作成します。SchemaChangePolicy で UPDATE_IN_DATABASE を設定すると、クローラー実行時にスキーマが更新されてもテーブル定義に自動的に反映されます。さらに詳細には、クローラー出力設定で "AddOrUpdateBehavior": "MergeNewColumns" を指定しておけば、新しい列が追加されてもマージされます
Amazon Athena
Amazon Athena は S3 のデータを SQL でクエリするサーバレスサービスです。Glue Data Catalog 上のテーブルを元に、Presto SQL ライクなクエリを実行できます。Athena は内部で Glue のメタデータを参照してデータを処理するため、ユーザーは通常のデータベースと同様にテーブルに対して SELECT 文を発行できます CloudFormation では AWS::Athena::WorkGroup でワークグループを作成し、出力場所(S3)や暗号化を設定できます。また、AWS::Athena::NamedQuery を使ってよく使うクエリを事前に定義することも可能です。例えば以下のように定義すると、Glue で作成されたデータベース・テーブルに対して SQL を実行できます
# Athena NamedQuery 定義例 (CloudFormation YAML)
SampleQuery:
Type: AWS::Athena::NamedQuery
Properties:
Name: "Sample-Query"
Database: !Ref GlueDatabase
QueryString: >-
SELECT *
FROM "mylogsdb"."my_logs_sample"
ORDER BY event_time DESC;
WorkGroup: !Ref AthenaWorkGroup
この例では、Glueデータベース mylogsdb のテーブル my_logs_sample に対して全件取得クエリを定義しています。こうして定義したクエリは Athena コンソールや API から実行できます。
Lambda関数の実装例(Python)
Lambda 関数内では Python を使い、boto3 ライブラリで Kinesis Data Streams にデータを送信します 以下はサンプルコードです:
import boto3
import json
import datetime
kinesis = boto3.client('kinesis')
def lambda_handler(event, context):
# イベントからログデータを生成または整形
data = {
'message': 'サンプルログデータ',
'timestamp': datetime.datetime.utcnow().isoformat()
}
# Kinesis Data Streams に JSON 文字列を送信
response = kinesis.put_record(
StreamName='MyKinesisStream',
Data=json.dumps(data), # JSONにシリアライズ
PartitionKey='partition_key' # シャード分散のキー
)
print("PutRecord Response:", response)
このコードでは、boto3.client('kinesis') でクライアントを作成し、put_record メソッドにストリーム名、JSON文字列、パーティションキーを渡しています。PartitionKey は同じ値のレコードを同じシャードに送るキーで、例では固定値ですが日時やユーザーIDなど動的にすることもできます。レスポンスには書き込み先シャードIDやシーケンス番号が含まれます。CloudFormation ではこの Lambda に対し、Kinesis ストリームへの PutRecord 権限を持つ IAM ロールを割り当てます。
Glue と Athena による自動スキーマ認識とクエリ
Glue クローラーを実行すると、S3 バケット内の新規データを自動的に走査してスキーマを推定し、Glue Data Catalog にテーブル定義が作成されます。これにより、データのスキーマを手動で作成せずに済むため、素早く分析を始められます。Glue ではディレクトリ構成に基づくパーティションも自動生成でき、例えば年月日フォルダ毎にパーティションを分けていた場合はクローラーがそれを検出してテーブルに組み込みます。さらに、CloudFormation の Crawler 設定でパーティション更新ポリシーを有効化すれば、新たなパーティションが現れた際にも自動でテーブルに反映されます
Athena では、Glue カタログのテーブルを「テーブル」として SQL クエリが可能です たとえば、SELECT 文でグループ集計を行ったり、特定条件でフィルタリングできます。Athena のクエリ実行結果は指定した S3 バケットにファイル出力され、コンソール上にテーブル形式で表示されます。また、Athena は Glue カタログを参照してデータを処理するため、スキーマ変更があっても Glue テーブルを最新化することでシームレスに分析が行えます。以下のように、Glue で作成されたデータベースとテーブルに対して SQL を記述できます(前節の NamedQuery 定義例も参照)
🗃️ S3に保存されたデータをAthenaで分析する簡単な実行例
ステップ1:Glue Crawlerを作成してS3のデータをカタログ化する
- AWSコンソールから「Glue」を開きます。
- 左側のナビゲーションで「クローラー」をクリック → 「クローラーの追加」を選択します。
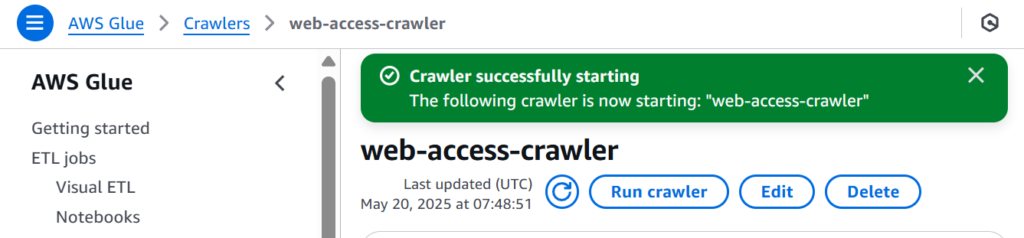
Run Crowlerを実行すれば、テーブルが作成、もしくは既存のテーブルがアップデートされます
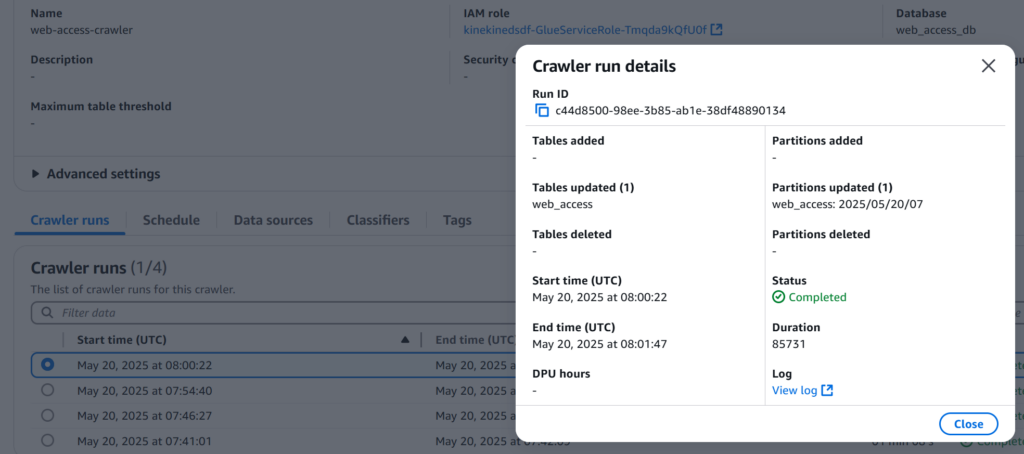
問題なければ成功するはずです
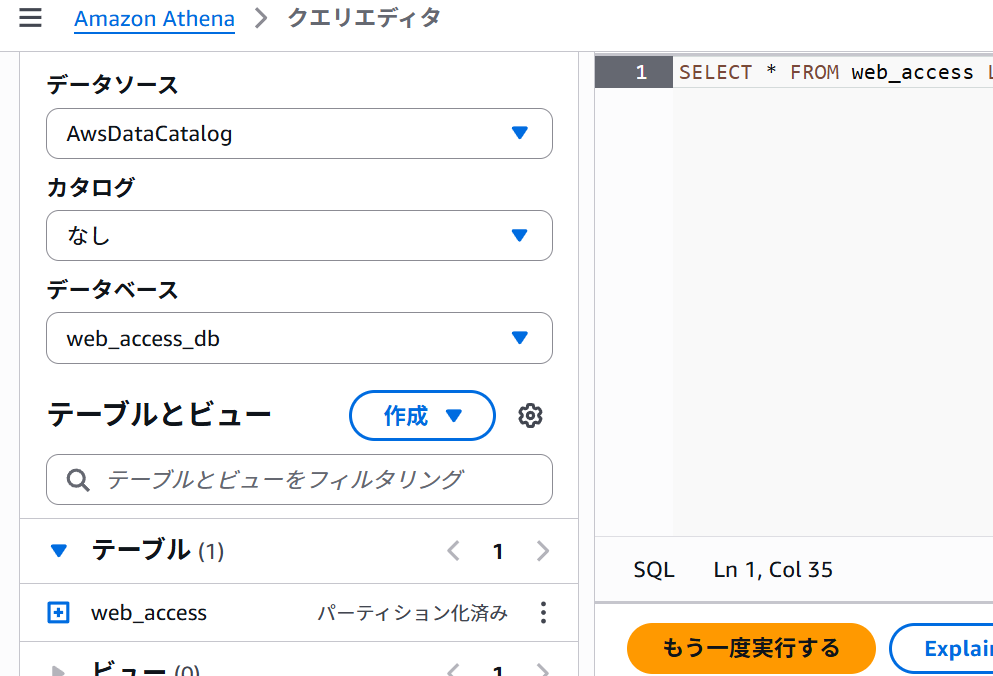
ステップ2:AthenaでSQLクエリを実行して分析する
- AWSコンソールで「Athena」を開きます。
- クエリエディタで、先ほどGlueクローラーで作成されたデータベースを選択します。
- 以下のようなSQLクエリを実行します:
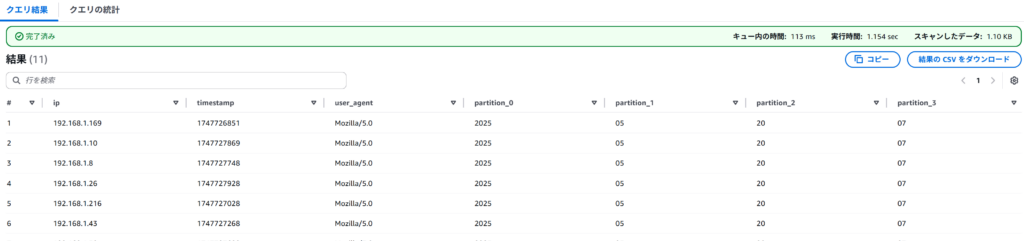
SELECT * FROM web_access LIMIT 100;無事クエリできたら下記のようになります
🔚 まとめ
このブログでは、以下のステップを通じてAWSによるリアルタイムデータ処理基盤を構築しました:
- CloudFormationでKinesis + Lambda + S3を自動構築
- Lambdaで処理しS3へ保存
- Glue + AthenaでSQL分析
最初は難しく感じるかもしれませんが、CloudFormationテンプレートを活用することで、構成の再現性が高まり、学習・運用の効率が大きく向上します。
ご希望があれば、この構成に API Gateway や リアルタイム可視化(QuickSight) を追加したり、 Parquet形式 に変換する例などもご紹介できます。
AWS初心者の方も、ぜひステップバイステップで挑戦してみてください!
