いいサイトを見つけたので、これに自分の感想をつける形で、まとめてみることにしました。この記事にある画像などは参考のために下記のサイトから引用させていただきます。
https://zenn.dev/moko_poi/articles/c2402f13a870a1
私は上記の記事は超大作で最高傑作だと思っています。上記URLに書かれている内容を知ったかぶりして、間違った答えを言ってしまうこともあるので、これをざっとなめてみることにする
名前解決、DNS、およびCDNの役割
URLは人間にとっては理解しやすいが、コンピュータやネットワーク機器はIPアドレスといざっとなめてみることにする最初のステップはこのドメイン名を対応するIPアドレスに「解決」することです。
DNSの役割
DNSサーバーは、ウェブサイトのドメイン名をIPアドレスに変換する役割を持ち、このプロセスを通じて、ブラウザはウェブサイトのホストサーバーに接続するための正確なアドレスを知ることができます。
DNSレコードのキャッシングにより、この名前解決プロセスは高速化され、再度同じウェブサイトにアクセスする際の遅延が減少します。
具体例:ブラウザに「example.com」と入力した場合
1. ローカルDNSキャッシュのチェック
あなたがブラウザに「example.com」を入力してEnterキーを押します。
ブラウザは最初に、ローカルマシンのDNSキャッシュをチェックして、「example.com」のIPアドレスがすでに存在するかを確認します。>>これを答えていなかった。「hosts fileを見る」としか答えてなかった。 例えば、ブラウザのキャッシュは下記のコマンドで見ることができる
chrome://net-internals/#dns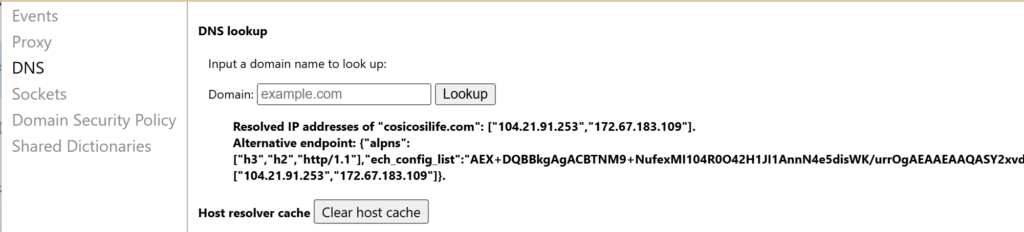
クリアしたいときは 上記の「Clear host cache」をクリック
それでもブラウザからアクセスする場合でもhosts fileが優先される場合が多いから、一応正解といえば正解。参照する順序は下記の通り
1 hostsファイルのエントリー:OSレベルで最優先される静的な設定。
特定のドメイン名とIPアドレスのペアを強制的に指定できます。
2 OSのDNSキャッシュ: hostsに記載がない場合、OSのDNSキャッシュを参照
3 ブラウザのDNSキャッシュ:上記に該当しない場合、ブラウザ内のキャッシュを確認。
4 DNSサーバーへの問い合わせ: キャッシュにない場合、指定されたDNSサーバーに問い合わせ。DNSサーバーへの問い合わせ:
- キャッシュにない場合、指定されたDNSサーバーに問い合わせ。
これは以前にアクセスしたことがあるウェブサイトの情報が一時的に保存されている場所です。
2. ISPのDNSサーバー
キャッシュにアドレスが見つからなかった場合、クエリはインターネットプロバイダー(ISP)のDNSサーバーに転送されます。実際はローカルDNSサーバに問い合わせに行く
1. ローカルDNSリゾルバー
通常、最初に問い合わせるのはOSまたはネットワーク設定で指定されたローカルDNSサーバーです。
ローカルDNSサーバーは、自分のキャッシュ内に問い合わせ対象の結果がある場合、それを返します。
例: 自宅のルーターに組み込まれたDNSサーバー、会社のDNSサーバー、またはプロバイダーのDNSサーバー。
2. 上位のリゾルバ(ISPのDNSサーバー)
ローカルDNSリゾルバーがキャッシュに情報を持っていない場合、上位のDNSサーバー(通常、インターネットサービスプロバイダー (ISP) のDNSサーバー)に問い合わせます。
ISPのDNSサーバーもキャッシュを持っており、キャッシュにヒットすればその結果を返します。
3. パブリックDNSサーバー
ISPのDNSサーバーがキャッシュに情報を持っていない場合、パブリックDNSサーバーが利用されることがあります。
パブリックDNSサーバーの例:
Google Public DNS: 8.8.8.8 / 8.8.4.4
Cloudflare DNS: 1.1.1.1 / 1.0.0.1
OpenDNS: 208.67.222.222 / 208.67.220.220
4. ルートDNSサーバー
パブリックDNSサーバーがキャッシュに情報を持っていない場合、ルートDNSサーバーに問い合わせます。
ルートDNSサーバーは、トップレベルドメイン(TLD)のDNSサーバー(例: .com, .jpなど)を管理しているサーバーの情報を返します。
5. TLD(トップレベルドメイン)DNSサーバー
ルートDNSサーバーから渡された情報を基に、TLDサーバーに問い合わせを行います。
TLDサーバーは、そのドメイン名の権威DNSサーバーを指定します。
6. 権威DNSサーバー
最終的に権威DNSサーバーに問い合わせを行い、そのドメイン名に対応するIPアドレスを取得します。権威DNSサーバーは、ドメイン所有者が設定したNSレコードに基づいて情報を管理しています。
ISPのDNSサーバーも、そのクエリの答えを持っていない場合に次のステップへと進みます。
もしISPのDNSサーバーが既にそのドメイン名のIPアドレスをキャッシュしている場合、それを直接クライアントに返し、これによりウェブサイトにすぐにアクセスすることが可能になります。>>>N社ではNTTとかに行ったら、彼らのキャッシュをクリアしてくれた。これはN社だからやってもらえる特別対応だったと思う
3. ルートDNSサーバーへのクエリ
ISPのDNSサーバーからルートDNSサーバーへクエリが送られます。
ルートDNSサーバーはインターネットのドメインネームシステム(DNS)の最上位に位置しており、主にドメインネームのトップレベルドメイン(TLD)への参照情報を提供します。
ルートDNSサーバーは直接リダイレクトするのではなく、適切なTLDサーバーへの参照リストを返すことで応答します。
4. TLDサーバー
ルートDNSサーバーからの情報を基に、ISPのDNSサーバーは「.com」などのTLDサーバーにクエリを送ります。
TLDサーバーはそのドメイン名(この場合は「example.com」)のネームサーバー情報を持っています。
TLDサーバーは、ドメイン名「example.com」に関連するオーソリティDNSサーバー(ネームサーバー)のアドレスを提供します。
5. オーソリティDNSサーバー
クエリが「example.com」のオーソリティDNSサーバーに到達します。
このIPアドレスは、ユーザーがアクセスしようとしているウェブサイトの実際の場所を示しています。
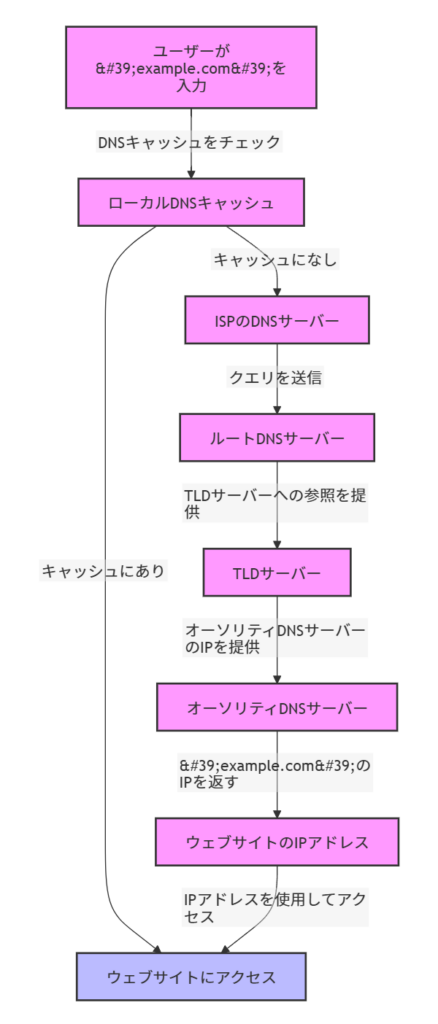
cosicosilife.com の場合お名前ドットコムから、クラウドフレアに権限移譲してあるから、TLDはNSとしてクラウドフレアに登録されているNSを参照してそのIPを返す
※ ISPのDNSサーバーにクエリがあった場合
補足:ISPのDNSサーバー、TLDサーバー、オーソリティのDNSサーバー
- ISPのDNSサーバー: インターネットにアクセスする際に最初に問い合わせるDNSサーバー。ユーザーの近くにあり、ドメイン名をIPアドレスに変換する手助けをします。よくアクセスされるウェブサイトの情報をキャッシュして、高速に応答します。
- TLDサーバー: トップレベルドメイン(例:.com、.jp)を管理し、そのドメイン下のウェブサイトの情報を指し示すサーバー。どのオーソリティDNSサーバーに問い合わせるべきかを教えてくれます。
- オーソリティDNSサーバー: 特定のドメイン(例:example.com)の「公式」情報を持つサーバー。そのドメインに関連するすべてのDNSレコードを持ち、ドメイン名を具体的なIPアドレスに変換します。
もう少しdig コマンドのトレースを詳細に見てみよう
dig cosicosilife.com +trace
; <<>> DiG 9.18.28-0ubuntu0.22.04.1-Ubuntu <<>> cosicosilife.com +trace
;; global options: +cmd
. 51 IN NS f.root-servers.net. # ルートDNSサーバーへの問い合わせ
. 51 IN NS d.root-servers.net.
. 51 IN NS c.root-servers.net.
. 51 IN NS a.root-servers.net.
. 51 IN NS i.root-servers.net.
. 51 IN NS g.root-servers.net.
. 51 IN NS b.root-servers.net.
. 51 IN NS k.root-servers.net.
. 51 IN NS h.root-servers.net.
. 51 IN NS l.root-servers.net.
. 51 IN NS j.root-servers.net.
. 51 IN NS e.root-servers.net.
. 51 IN NS m.root-servers.net.
;; Received 811 bytes from 127.0.0.53#53(127.0.0.53) in 1 ms
>>上記からまずルートを見つけ出す。ルートはトップレベルドメイン(TLD)に関する情報を提示。
com. 172800 IN NS c.gtld-servers.net. # TLD DNSサーバーへの問い合わせ
com. 172800 IN NS b.gtld-servers.net.
com. 172800 IN NS g.gtld-servers.net.
com. 172800 IN NS f.gtld-servers.net.
com. 172800 IN NS k.gtld-servers.net.
com. 172800 IN NS j.gtld-servers.net.
com. 172800 IN NS i.gtld-servers.net.
com. 172800 IN NS h.gtld-servers.net.
com. 172800 IN NS e.gtld-servers.net.
com. 172800 IN NS d.gtld-servers.net.
com. 172800 IN NS a.gtld-servers.net.
com. 172800 IN NS l.gtld-servers.net.
com. 172800 IN NS m.gtld-servers.net.
com. 86400 IN DS 19718 13 2
;; Received 1204 bytes from 192.33.4.12#53(c.root-servers.net) in 104 ms
>>>c.root-servers.netが応答する。c.root-servers.netは権威サーバーであり、TLDのサーバーに関する情報を返す。
cosicosilife.com. 172800 IN NS greg.ns.cloudflare.com. # 対象ドメインのネームサーバー(NS)情報を返す
cosicosilife.com. 172800 IN NS linda.ns.cloudflare.com.
;; Received 719 bytes from 192.5.6.30#53(a.gtld-servers.net) in 117 ms
>>>このリクエストはa.gtld-servers.netというTLDサーバーから受け取る。ここでcosicosilife.comのNS(ネームサーバー)情報が返される。
cosicosilife.com. 300 IN A 104.21.91.253 # AレコードによりIPアドレスを返す
cosicosilife.com. 300 IN A 172.67.183.109
cosicosilife.com. 300 IN RRSIG A 13 2 300 20250126033858 20250124013858 34505 cosicosilife.com. # DNSSEC署名、セキュリティ情報
;; Received 189 bytes from 172.64.32.250#53(linda.ns.cloudflare.com) in 4 ms
>>>クラウドフレアのNSサーバー(linda)がAレコードを持っているため、実際のIPアドレス情報を返す。
それではうまくいかない場合はどうなるか、あまりうまくいかなかったことでdig コマンドを打鍵したことがなかったのでまとめてみる
| ステータスコード | 説明 |
| NOERROR | 名前解決が成功し、要求されたリソースレコードが返された。 |
| NXDOMAIN | 指定したドメイン名が存在しない(DNSに登録されていない)。 |
| SERVFAIL | DNSサーバーがリクエストを処理できなかった(サーバーエラーや設定の問題など)。 |
| REFUSED | DNSサーバーがリクエストを拒否した(権限やアクセス制限に関する問題)。 |
| FORMERR | クエリの形式が不正で、DNSサーバーがリクエストを理解できなかった。 |
| NOTIMP | DNSサーバーが要求された操作(例:AXFR)をサポートしていない。 |
| YXDOMAIN | DNSサーバーがリクエストされたドメイン名が存在すると誤認し、予期しない状態でレコードが返された。 |
| NXRRSET | 特定のリソースレコード(RR)が存在しない(NXDOMAINに似ているが、リソースレコードに関するエラー)。 |
| NOTZONE | 名前解決時に指定されたドメイン名が現在のゾーン外である(ゾーン転送に関するエラー)。 |
CDNの最適化
DNS解決が行われた後、CDNを通じたコンテンツ配信が行われます。(例えば、CNAMEレコードを使用してCDNプロバイダーを指す場合)
グローバルに分散したサーバーネットワークを利用して、ユーザーにより近い場所からウェブコンテンツを迅速に配信します。地理的に近いサーバをクラウドフレアが選んでいるという仕組みがユニキャストでこちらにまとまっている
https://qiita.com/appare45/items/e78bb5b5625473638cad
CDNは、特に大きなファイルやメディアコンテンツを扱うサイトでその効果を発揮し、レスポンス時間の短縮、サーバーの負荷軽減します。
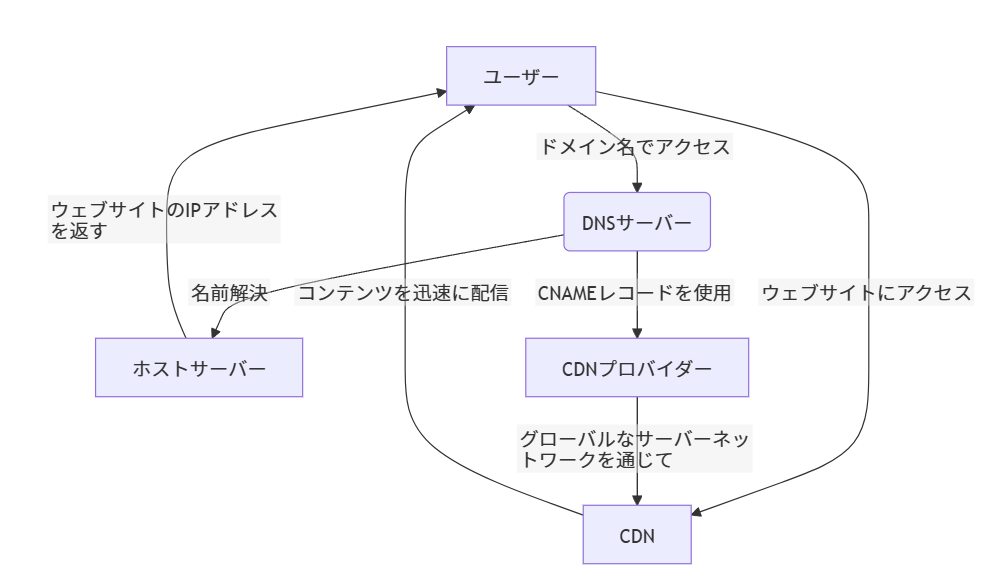
CDNの仕組み
- コンテンツのキャッシュ:
- CDNのエッジサーバーは、オリジンサーバーからコンテンツ(HTMLページ、画像、動画、スタイルシート、JavaScriptファイルなど)をコピーし、キャッシュ(一時的に保存)します
- 地理的な近さ:
- ユーザーがウェブサイトにアクセスすると、DNS解決プロセスにより、ユーザーに最も近いCDNのエッジサーバーが選択されます。これにより、データが長距離を移動する時間が短縮され、ウェブページのロード時間が改善されます。
- 負荷分散:
- CDNは、コンテンツのリクエストを複数のエッジサーバーに分散させることで、特定のサーバーにかかる負荷を均等に分けます。これにより、高トラフィック時でもコンテンツの高速配信を維持し、サーバーの過負荷を防ぎます。
- コンテンツ最適化:
- 一部のCDNは、配信するコンテンツを自動的に最適化する機能を提供します。例えば、ユーザーのデバイスやブラウザに応じて画像サイズを調整したり、動画のビットレートを最適化したりします。
- セキュリティの向上:
- CDNは、DDoS攻撃などのサイバー脅威からウェブサイトを保護する役割も担います。分散したエッジサーバーを利用してトラフィックをフィルタリングし、攻撃を緩和することができます。
2. Webサイトアクセスとセキュアな通信
ユーザーのブラウザがCDNのエッジサーバー(または最終的なウェブサーバー)に接続すると、TLSハンドシェイクが行われます。
ユーザーがWebブラウザを使用してECサイトにアクセスする際、HTTP/HTTPSプロトコルを通じて安全なデータ交換が行われます。
HTTPSはTLS(トランスポート層セキュリティ)を利用して通信を暗号化し、TLS証明書によってサーバーの身元を証明します。
これにより、ユーザーとサイト間の通信が保護され、信頼できる安全な接続が確立されます。
HTTPS通信の暗号化とTLS証明書による正当性の確認は、以下のステップで行われます
1. TLSハンドシェイク
- クライアントハロー: ブラウザ(クライアント)がサーバーに接続し、使用可能な暗号化方式やTLSのバージョンなどの情報を送信します。
- サーバーハロー: サーバーはクライアントに応答し、共通の暗号化方式やTLSのバージョンを選択し、自身のTLS証明書をクライアントに送信します。実際に証明書を利用するのは、クライアントとの直接的な通信を担うロードバランサーの場合が多い
2. TLS証明書の検証
- 証明書の検証: ブラウザは受け取ったTLS証明書を検証します。これには、証明書が信頼できる認証局(CA)によって発行されていること、有効期限内であること、そしてサイトのドメイン名と一致していることを確認します。
- Webブラウザや他のクライアントアプリケーションに組み込まれているセキュリティ機能によって検証は自動的に行われます
3. 暗号化キーの交換
- キー交換: サーバーとクライアントは、セッション中に使用する暗号化キーを安全に交換します。これにより、以降の通信はこのキーを使用して暗号化されます。
1. クライアントハロー:
クライアント(ブラウザ) -----> サーバー
[送信内容]
・対応可能なTLSバージョン
・対応可能な暗号化方式(例: AES, RSA)
・ランダムデータ(クライアントランダム)
2. サーバーハロー:
クライアント(ブラウザ) <----- サーバー
[送信内容]
・選択されたTLSバージョンと暗号化方式
・ランダムデータ(サーバーランダム)
・TLS証明書(サーバーの公開鍵を含む)
3. TLS証明書の検証:
クライアント(ブラウザ)
[動作内容]
・証明書の有効性を確認
- 信頼された認証局(CA)による署名か?
- 有効期限内か?
- ドメイン名が一致しているか?
4. 暗号化キーの交換(キー交換):
クライアント(ブラウザ) -----> サーバー
[送信内容]
・鍵交換アルゴリズム(例: ECDHE)に基づいて生成したクライアントキー
・クライアントキーはサーバーの公開鍵で暗号化されて送信
5. セッションキーの生成:
クライアント(ブラウザ) ⇔ サーバー
[動作内容]
・クライアントランダム + サーバーランダム + 共有鍵(鍵交換アルゴリズムで生成)を基にセッションキーを生成
・以降の通信はこのセッションキーで暗号化される
鍵交換アルゴリズムは以下の三つが主。
- RSA鍵交換
- DHE(Ephemeral(一時的) Diffie-Hellman)鍵交換
- ECDHE鍵交換(Ephemeral elliptic curve(一時的楕円曲線) Diffie-Hellman)
RSAはサーバの秘密鍵が流出すると、過去の暗号データすべてが復元可能になる(前方秘匿性がない)という脆弱性を持っているため使わず、通常はDHEやECDHEを使います。
それでは証明書の検証に失敗する例などをいくつか挙げてみよう
| 失敗の種類 | 理由 | 影響 | 対処法 |
|---|---|---|---|
| 証明書が信頼できるCAによって署名されていないNET::ERR_CERT_AUTHORITY_INVALID | 証明書が自己署名されている、または信頼できないCAによって発行されている | 接続が安全でないとみなされる | 信頼できるCAから証明書を取得する。例えば、Let’s Encryptなどの無料CAを利用。 |
| 証明書の有効期限が切れている NET::ERR_CERT_DATE_INVALID | 有効期限が現在の日付より前 | 接続エラーが発生 | 有効期限が切れる前に証明書を更新する。自動更新機能(例: Certbot)を利用して管理を効率化。 |
| ドメイン名の不一致 NET::ERR_CERT_COMMON_NAME_INVALID | 証明書のドメイン名とアクセスURLが一致しない | 証明書が無効とみなされる | 証明書発行時に正しいドメイン名を設定する。ワイルドカード証明書(例: *.example.com)を使用すると柔軟性が向上。 |
| 証明書チェーンの問題 | 中間証明書が正しく提供されていない、またはルート証明書が信頼ストアに存在しない | 信頼性を検証できずエラーが発生 | サーバー設定で完全な証明書チェーン(中間証明書を含む)を提供するよう設定する。 |
| 証明書の取り消し(失効)NET::ERR_CERT_REVOKED | 証明書が失効している(CRLまたはOCSPで確認) | 接続が拒否される | 証明書が失効している場合、直ちに新しい証明書を発行し、サーバーで更新する。 |
| TLSバージョンや暗号スイートの非互換性 NET::ERR_SSL_OBSOLETE_VERSION ERR_SSL_PROTOCOL_ERROR | 古いTLSバージョン(例: TLS 1.0)や非推奨アルゴリズム(例: SHA-1)を使用している | 接続の確立に失敗 | 最新のTLSバージョン(TLS 1.2/1.3)を使用する。セキュリティポリシーを更新し、非推奨の暗号スイートを無効化。 |
| ネットワークや設定の問題Your connection is not private | ファイアウォールやプロキシが証明書を差し替えている、またはサーバーの設定ミスで誤証明書提供 | 接続が安全でないと判断される | サーバー構成を確認し、正しい証明書を提供する。必要に応じてプロキシやファイアウォール設定を調査・修正。 |
4. 通信の暗号化
- セキュアな通信: キー交換が完了すると、サーバーとクライアント間の通信はすべて暗号化されます。送受信されるデータは、外部からの盗聴や改ざんが困難な状態で保護されます。
鍵交換アルゴリズムは以下の三つが主。
- RSA鍵交換
- DHE(Ephemeral(一時的) Diffie-Hellman)鍵交換
- ECDHE鍵交換(Ephemeral elliptic curve(一時的楕円曲線) Diffie-Hellman)
RSAはサーバの秘密鍵が流出すると、過去の暗号データすべてが復元可能になる(前方秘匿性がない)という脆弱性を持っているため使わずに、通常はDHEやECDHEを使います。
参照:https://www.serotoninpower.club/archives/360/#要素技術-2-鍵交換
5. 通信の終了
- セッションの終了: 通信が終了する際には、双方がセッションを終了し、使用した暗号化キーを破棄します。次回の通信時には新たなキーが交換され、再びセキュアな通信が行われます。
補足
- TLSセッション: セキュアな通信を行うための、クライアントとサーバー間の維持される接続。一つのセッションは複数のリクエストとレスポンスにわたって使用され、通信を暗号化するためのキーを共有します。
- HTTPセッション: Webアプリケーションでユーザーの状態やデータを複数のリクエストにわたって保持するためのメカニズム。セッションIDによってユーザーを識別します。
毎回の1リクエストに対して新たなセッションが開始されるわけではなく、一定の期間(またはユーザーがアクティブである間)維持されることが多い
そのため毎回ハンドシェイクが行われるわけではないです。
異なるブラウザでは、異なるTLSセッションが使用されます。
ユーザーのブラウザ(クライアント)
|
|--- クライアントハロー --->|
| |
|<-- サーバーハロー ---------|
Webサーバー |
(サーバー) |
|--- TLS証明書の送信 ------->|
| |
|<-- 証明書の検証 ----------|
| |
|--- 暗号化キーの交換 ------>|
| |
|<-- 暗号化通信の開始 -------|
| |
|--- セキュアな通信 -------->|
| |
|<-- セキュアな通信 ---------|
| |
|--- 通信の終了 ------------>|
| |
|<-- セッションの終了 -------|
3. 安全なアクセス・セキュリティ
ECサイトへのアクセスは、複数のセキュリティ層を通過することで保護されます。
代表的なものとして、ファイアウォール、Webアプリケーションファイアウォール(WAF)、およびDDoS攻撃防御システムなどがあります。
ファイアウォールとは
不正なトラフィックがネットワークに侵入するのを防ぎます。これにより、ウェブサーバーが悪意あるアクセスから保護され、ユーザーのデータが安全に保たれます。
Webアプリケーションファイアウォール(WAF)
ウェブアプリケーションを標的とする攻撃(例えば、SQLインジェクションやクロスサイトスクリプティング)から保護するために設計されています。WAFは、ウェブアプリケーションへのリクエストを監視し、悪意のある試みを検出してブロックします。
DDoS攻撃防御
DDoS(分散型サービス拒否)攻撃は、サーバーを過負荷状態に陥らせ、正当なユーザーのアクセスを妨げることを目的としています。DDoS攻撃防御システムは、異常なトラフィックの増加を検出し、攻撃トラフィックをフィルタリングすることで、ウェブサイトの可用性を維持します。
WAFの配置について
複数の場所に配置することが可能です。
一般的には以下のような構成にされることが多いです。
インターネット
|
|---- CDN ----------------------> 静的コンテンツ
| (HTML/CSS/JS等のフロントエンド資源)
| SPAのフロントエンド
|
|---- WAF ----> ALB ---> APIサーバー
(ビジネスロジックやデータベースアクセスを処理)
入ってくる全てのトラフィック(CDNを介した静的コンテンツのリクエストと、直接ALBに向けられたAPIリクエスト)をフィルタリングします。これにより、攻撃からアプリケーション層を保護し、セキュリティを強化します。
補足AWSで現在 WAFと組み合わせて使用できるのは、CloudFront、ALB、API Gateway
WAFの使い方
主な機能は、入ってくるトラフィックをリアルタイムで監視し、ウェブアプリケーションに対する潜在的な攻撃を検出してブロックします。
WAFは、HTTP/HTTPSトラフィックを解析し、アプリケーション層(OSIモデルの第7層)での攻撃を検知します。
ポリシー設定
SQLインジェクション防御ポリシー:
「ユーザー入力フィールドでは、特定のSQLキーワード(例:SELECT、INSERT、DELETE)や特殊文字(例:シングルクォート)の使用を禁止する」。
このポリシーは、フォーム入力やURLパラメータを介して不正なSQLコマンドがデータベースに送信されるのを防ぎます。
有名なケースだと「’ OR ‘1’=’1」」などがある
クロスサイトスクリプティング(XSS)防御ポリシー:
「ユーザーからの入力やクエリパラメータに含まれるHTMLタグやJavaScriptコードは、表示前にサニタイズ(無害化)する」。
これにより、悪意のあるスクリプトがウェブページに挿入され、他のユーザーに実行されるのを防ぎます。
「<script>malicious code</script>」など
トラフィック分析
異常なリクエストパターン検出: 短時間に多数のリクエストが同一のIPアドレスから送られてくる場合、WAFはこれを自動的に検出し、DDoS攻撃やブルートフォース攻撃の可能性があると判断します。
例えば、「5分間に100回以上のログイン試みがあった場合、そのIPアドレスからのアクセスを一時的にブロックする」というポリシーを設定できます。
WAFにおけるIPフィルタリング
IPブラックリスト, IPホワイトリスト, 地理的ブロック, レートリミット …
4. 負荷分散・ロードバランサー
ロードバランサーの基本
ロードバランサーは、入ってくるネットワークトラフィックを複数のサーバー(例: アプリケーションサーバー)間で分散させるデバイスまたはソフトウェアです。このプロセスにより、単一のサーバーへの負荷が軽減され、全体の処理能力が向上し、レスポンスタイムが改善されます。
種類
- アプリケーションロードバランサー (ALB): アプリケーション層(第7層)で動作し、HTTP/HTTPSトラフィックの負荷を分散します。リクエストの内容(例: 使用されるURLやヘッダー情報)に基づいてルーティング決定を行います。
- ネットワークロードバランサー (NLB): 第4層で動作し、IPプロトコルデータを基にトラフィックを分散します。高性能と低遅延が要求される場合に適しています。
負荷分散戦略
- ラウンドロビン: サーバー群に順番にリクエストを割り当てるシンプルな戦略です。サーバーの処理能力が均等である場合に適しています。
- 最少接続数: 現在最も少ない接続数を持つサーバーにリクエストを割り当てます。各サーバーの負荷を平等に保つことができます。
- IPハッシュ: クライアントのIPアドレスを基にハッシュ関数を適用し、その結果に基づいてサーバーを選択します。同じクライアントからのリクエストは常に同じサーバーにルーティングされるため、セッションの持続性を保証します。
高可用性と冗長性
最初でも述べた通り、ロードバランサーを利用する主な目的の一つは、高可用性を確保することです。サーバーの一部がダウンした場合でも、ロードバランサーはトラフィックを健全なサーバーに自動的にリダイレクトすることで、サービスの中断を最小限に抑えます。
このため、ロードバランサー自体も冗長構成を取ることが一般的です。
補足:
AWSのロードバランサーを利用している場合は、複数のアベイラビリティゾーン(AZ)にまたがって自動的にデプロイされており、トラフィックに応じて自動的にスケールアップ・ダウンします。
Application Load Balancer とは? – Elastic Load Balancing
ここまではロードバランサーについて解説したのですが、関連する一般的な疑問や利用の背後にあるさらなる理由などについて解説します
セッション持続性(スティッキーセッション)
特定のクライアントからのリクエストを常に同じサーバーにルーティングする機能。
Application Load Balancer のスティッキーセッション – Elastic Load Balancing
補足
awsでスティッキーセッションを指定する場合は、1秒から7日までの範囲です。
1 〜 604800秒
ヘルスチェック
ロードバランサーは、バックエンドのサーバーが正常に動作しているかどうかを定期的にチェックします。ヘルスチェックに失敗したサーバーは、トラフィックのルーティング対象から一時的に外され、障害が発生したサーバーにリクエストが送られることを防ぎます。
このようなヘルスチェックのことを死活監視と言います。
補足
24年2月から、ALBの設定からワンクリックでWAFを設定できるようになりました。
AWS Application Load Balancer がワンクリック WAF 統合を発表
5. アプリケーションサーバー(APサーバー)・APIサーバー
ここまで来てようやくサーバーとの通信が発生します。
アプリケーションサーバーとAPIサーバーは、現代のウェブアプリケーションやサービスのバックエンドにおいて中心的な役割を担います。これらのサーバーは、クライアントからのリクエストを受け、必要なビジネスロジックの処理とデータベースとのやり取りを行い、最終的にはクライアントに対して動的なコンテンツやAPIレスポンスを提供します。
アプリケーションサーバー
アプリケーションサーバーは、Webアプリケーションのビジネスロジック層を実行するためのプラットフォームです。クライアント(例えば、Webブラウザやモバイルアプリ)からのリクエストを受け取り、必要な処理(例えば、データの検索、加工、保存など)を行った後、適切なレスポンスをクライアントに返します。
アプリケーションサーバーは、セッション管理、トランザクション管理、セキュリティ、データベース接続の管理など、複雑なビジネスプロセスをサポートする機能を提供します。
APIサーバー
外部のアプリケーションやサービスが利用可能なAPI(アプリケーションプログラミングインターフェース)を提供します。
サードパーティの開発者がアプリケーションの機能やデータにプログラム的にアクセスできるようになります。APIサーバーはRESTful APIやGraphQLなどの技術を使用して、データの取得、更新、削除などの操作を効率的に行うことができます。
ステートレスとステートフルの処理
- ステートレス: APIサーバーは基本的にステートレスであり、各リクエストはそれ自体で完結しています。このため、リクエスト間でユーザーの状態を保持する必要がなく、水平スケール(横方向の拡張)を容易に行うことができます。
- ステートフル: 一方で、セッション情報やユーザーの状態を維持する必要がある場合はステートフルな処理が必要となります。ステートフルな処理は、ロードバランサーのスティッキーセッション機能などを利用して、特定のユーザーのリクエストを同じサーバーインスタンスにルーティングすることで対応します。
アーキテクチャパターン
- モノリシック: シングルコードベースのアプリケーション。開発がシンプルだが、大規模化すると管理が複雑になる。
- サービス指向アーキテクチャ (SOA): 複数のアプリケーションやシステムでビジネスロジックを提供するシステム構成。エンタープライズサービスバスを介してサービス間連携DBを共有しているため、同期などの処理が必要ない。
- マイクロサービス: ビジネスロジックを細分化して個々のサービスとしたアーキテクチャ。APIを介して通信、DBを分けているため、データが重複する可能性もある
モノリシックアーキテクチャ
Browser -> [Application] -> Database
サービス指向アーキテクチャ (SOA):
Browser -> エンタープライズサービスパス -> [Service 1] -> Database
[Service 2]
[Service 3]
マイクロサービスアーキテクチャ:
Browser -> [RestAPI -> 機能 1 -> Database 1]
[RestAPI -> 機能 2 -> Database 2]
[RestAPI -> 機能 3 -> Database 3]
6. インメモリデータベース(Memcached, Redis)・キャッシュ
ようやくデータベースに接続するかと思った方もいると思いますが、トラフィックが多いプロダクトやreadが多い場合は、キャッシュサーバーを挟むことが多いです。
この問題に対処するために、MemcachedやRedisなどのインメモリデータベースを活用するキャッシュ戦略を導入することが多くなっています。
インメモリデータベースとは
データをRAM(メモリ)に格納して、高速な読み込みと書き込みを実現します。ディスクベースのデータベースと比較して、アクセス速度が格段に速く、リアルタイム処理に適しています。
MemcachedとRedisの違い
Memcachedは、シンプルなkey-valueストアであり、主にセッションキャッシュや単純なデータ格納に使用されます。マルチスレッドをサポートしており、これにより複数のコアを持つサーバー上での性能が向上します。
Redis、リスト、ハッシュ、セット、ソートされたセット、ビットマップなどの多様なデータ型をサポートしています。
パーシステンスオプションというディスクへのデータ永続化機能を備えており、キャッシュだけでなく、一定のデータストレージとしても使用できます。
また、アトミック操作をサポートしており、カウンターのインクリメントやリストへの追加などの操作を安全に実行できます。
シングルスレッドで動作しますが、非常に効率的なイベント駆動モデルを使用しており、多くのユースケースにおいて十分なパフォーマンスを提供します。
キャッシュの実装戦略
- キャッシュアサイド
- リード/ライトスルー
- ライトビハインド
キャッシュアサイド (Cache-Aside)
アプリケーションコードがキャッシュとデータソースの両方を管理します。
データの要求があったとき、まずキャッシュを確認し、データが存在しない場合にのみデータベースにアクセスします。
データを取得したら、それをキャッシュに格納し、後続の要求に備えます。
利点: アプリケーション側のコードがシンプルに保てキャッシュミス時のデータ読み込み処理を自動化できる
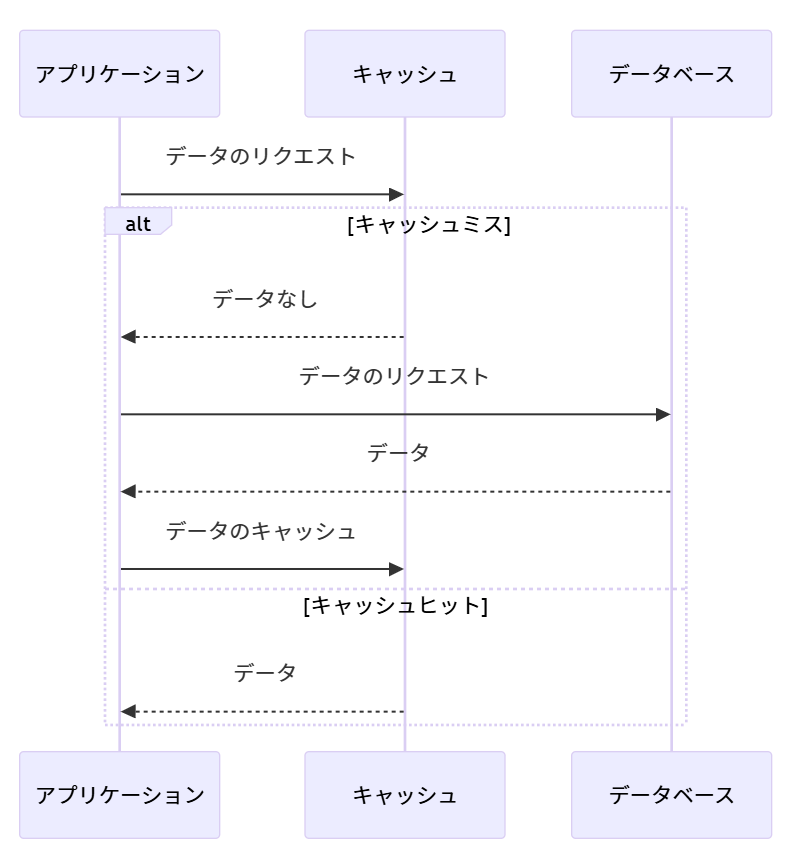
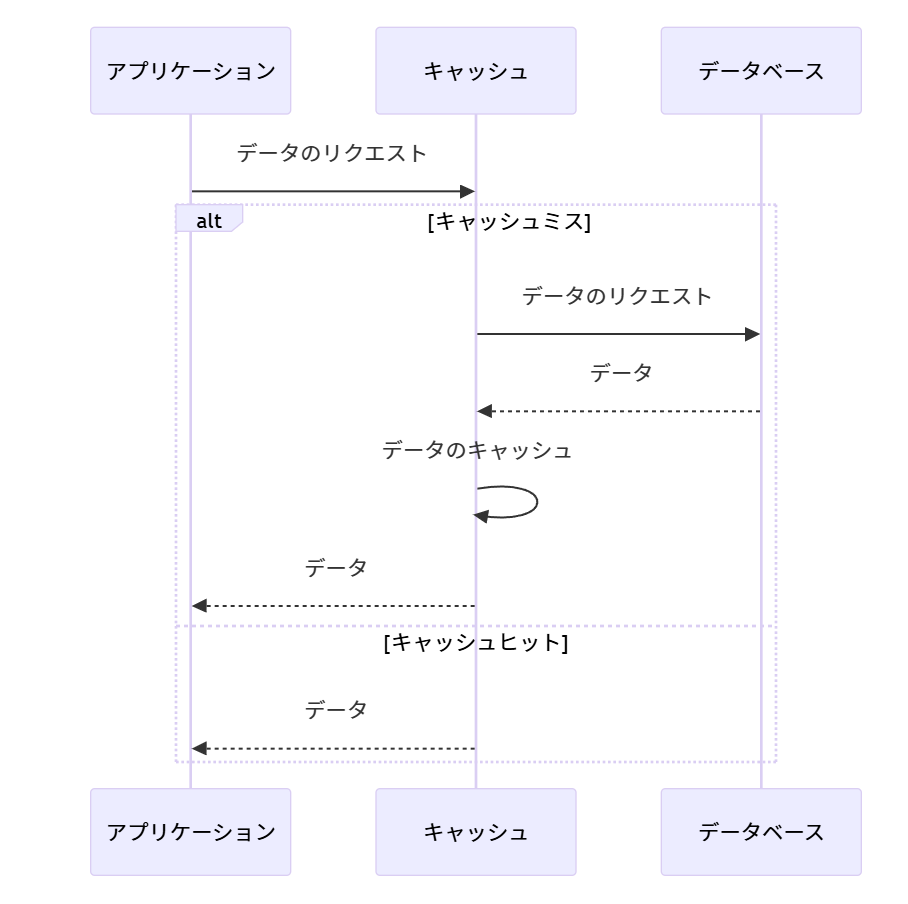
リードスルー (Read-Through)
キャッシュ層がデータの読み込みを管理します。データ要求時にキャッシュにデータがなければ、キャッシュ層がデータベースからデータを読み込み、キャッシュに格納してからアプリケーションに返します。
利点: アプリケーション側のコードがシンプルに保てる。キャッシュミス時のデータ読み込み処理を自動化できる。
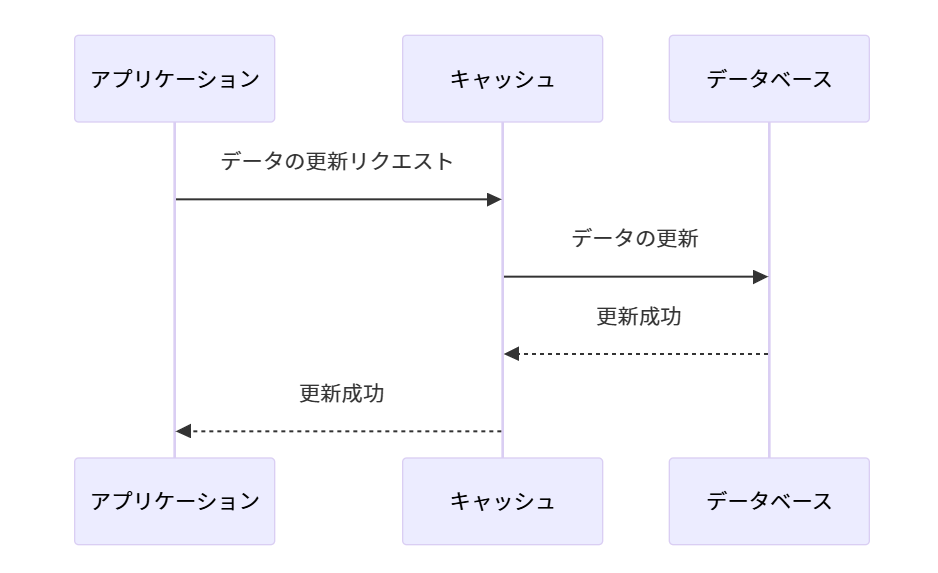
ライトスルー (Write-Through)
書き込み操作もキャッシュ層が管理します。アプリケーションからのデータ書き込み要求を受けた場合、キャッシュ層がまずデータをデータベースに書き込み、その後キャッシュにも同じデータを格納します。
利点: データの整合性が保たれ、データベースとキャッシュ間での同期処理を自動化できる。
欠点: データ書き込みの際に常にデータベースにアクセスするため、書き込み性能が低下する可能性があります。
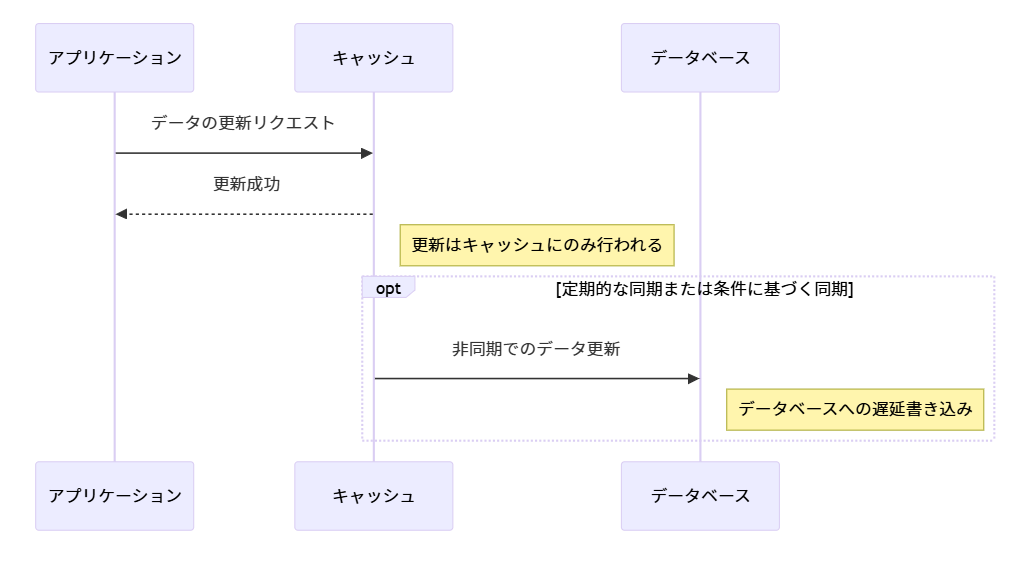
ライトビハインド (Write-Behind)
データの書き込みを一時的にキャッシュに保持し、バッチ処理または遅延処理によって後でデータベースに書き込む方法です。これにより、書き込み操作のパフォーマンスを向上させることができます。
利点: 書き込み操作の高速化。データベースへの負荷を減らすことができます。
欠点: データベースとキャッシュ間の同期を管理する必要があり、データの整合性を保つための追加の仕組みが必要になる場合があります。
7. データベース(DB)
知っていると思いますがデータベースは、大量のデータを効率的に管理し、処理するためのシステムです。現在のアプリケーションではデータを永続化するだけではなく、高速なデータアクセス、スケーラビリティ、そして信頼性が求められます。
これらの要求を満たすために、データベース技術ではいくつかの重要な概念が採用されています。以下に、その主要な技術について解説します。
インデックス
データベースでデータの検索速度を向上させるために使用されます。
データベース内のテーブルにインデックスを設定することで、特定の列のデータを迅速に探索できるようになります。
インデックスは、データベースのパフォーマンスを大幅に改善することができますが、過剰に使用すると、データの更新時にパフォーマンスが低下する可能性があるため、適切なバランスが重要。
例:本屋のカタログシステム books
| Book ID | Title | Author | Genre | Year |
|---|---|---|---|---|
| 1 | The Great Gatsby | F. Scott Fitzgerald | Fiction | 1925 |
| 2 | War and Peace | Leo Tolstoy | Fiction | 1869 |
| … | … | … | … | … |
インデックスの作成:
- データベースは、タイトル名をキーとして
idx_titleという名前のインデックスを作成を作成します。 - インデックスが作成されると、
title列の検索が高速になります。
CREATE INDEX idx_title ON books (title);検索時の利用:
- ユーザーが特定のタイトル(例: 「War and Peace」)を検索します。
- インデックス
idx_titleが存在するため、データベースはインデックスを使用して検索し、全ての行をスキャンすることなく迅速に結果を見つけることができます。
SELECT * FROM books WHERE title = 'War and Peace';- 直接アクセス:
- データベースは内部的に
idx_titleインデックスを参照し、対象のタイトルを含む行へ直接アクセスします。 - テーブル全体をスキャンする必要がなくなるため、検索速度が大幅に向上します。
- データベースは内部的に
- インデックスの更新:
- 新しい本が
booksテーブルに追加されたり、既存の本のタイトルが変更されたりすると、データベースは自動的にidx_titleインデックスを更新します。
- 新しい本が
INSERT INTO books (title, author, genre, year) VALUES ('New Book Title', 'Author Name', 'Genre', 2021);レプリケーション
データを複数のデータベースサーバー間でコピーまたは同期するプロセスを指します。
これにより、データの冗長性が確保され、データベースの可用性と耐障害性が向上します。
目的は、データのバックアップ、読み取り処理の分散、データベースの地理的分散、災害復旧など多岐にわたります。
実装方式
- マスタースレーブ構成
- ピアツーピア(マルチマスター)
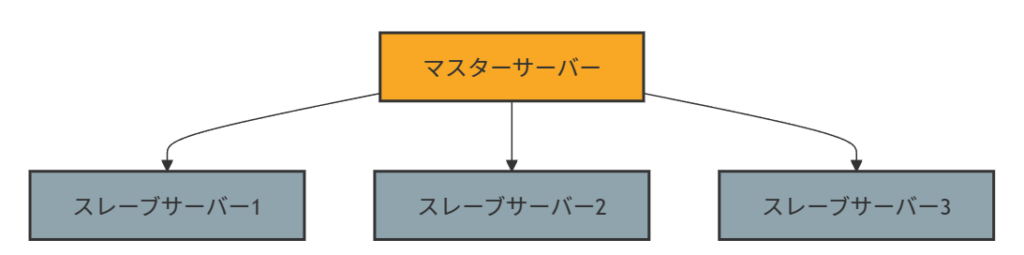
マスタースレーブ構成
一つのマスターサーバーが書き込み(更新、削除、挿入)を担当し、そのデータを一つ以上のスレーブサーバーに複製します。
スレーブサーバーは読み取り専用または読み取り優先で、この構成は読み取り負荷の分散とデータのバックアップに効果的です。
スレーブはマスターからのデータ変更を継続的に受け取りますが、スレーブからマスターへのデータのフィードバックはありません。
https://embed.zenn.studio/mermaid#zenn-embedded__4371e054053d4
ピアツーピア(マルチマスター)
複数のサーバー間でのデータの複製を指します。このシステムでは、あるサーバーで行われた変更が他の全サーバーに複製され、すべてのサーバーがデータに対して等しい所有権を持ちます。つまり、どのサーバーも「マスター」ではなく、全てが対等(ピア)です。
複数のサーバーが同じデータを同時に更新することがあり得るため、競合が発生する可能性があります。
この競合は、バージョン情報を含む追加の列と、更新時のタイムスタンプ情報を使用して自動的に解決されます。最終的に、最新のタイムスタンプを持つ更新が保持され、他のサーバーにその変更が伝播されます。
Read/Write構成
Read/Write構成は、データベースの処理能力を最大化するために、データの読み出し(Read)と書き込み(Write)処理を物理的または論理的に分離するアーキテクチャ設計です。
リードレプリカを複数配置することで可用性が高まり、 読み出しリクエストをリードレプリカに分散することで、マスターデータベースの負荷を軽減し、より多くの書き込みトランザクションを処理できるようになります。
書き込み専用データベースではトランザクションログの最適化に焦点を当て、読み出し専用データベースではクエリ応答時間の短縮に注力できます。
Read/Writeの差分同期
書き込みデータの変更を読み出し専用データベース(リードレプリカ)に同期する必要があります。
- 非同期レプリケーション: 最も一般的な方法で、マスターデータベースでのトランザクションコミット後に、変更がリードレプリカに複製されます。この方法では、レプリケーション遅延が発生する可能性がありますが、マスターデータベースのパフォーマンスに影響を与えません。
- 同期レプリケーション: 書き込み操作がマスターデータベースとリードレプリカの両方でコミットされるまで完了しません。これにより、データの一貫性が保証されますが、レプリケーションの遅延が書き込みレイテンシに直接影響します。
- ログシッピング: この方法では、マスターデータベースのトランザクションログを定期的にリードレプリカにコピーし、リードレプリカがそのログを再生してデータを更新します。ログシッピングは、レプリケーション遅延を許容できるシナリオで有効です。
シャーディング
データを複数のデータベース(シャード)に分散させることで、単一のデータベースにかかる負担を減らし、読み書き操作の速度を向上させることができます。
スケーラビリティ:データベースのサイズを超えるデータを扱うことができ、データが複数のシャードに分散されるため、単一のデータベースサーバーに対する負荷が軽減されます。
パフォーマンス:各シャードが独立して動作するため、並列処理が可能になり、読み書き操作のレイテンシが低下します。
シャーディング手法
垂直シャーディング(Vertical Sharding):
- データベースの異なるテーブルを別々のデータベース(シャード)に分割します。各シャードは、データベース内の異なる機能領域を担当します。
水平シャーディング(Horizontal Sharding):
- 同一のテーブルのレコードを複数のデータベース(シャード)に分散させます。これは、特定の列の値(例: 顧客IDや地理的な位置)に基づいて行われることが多いです。
キーベースのシャーディング(Key-based Sharding):
- データをシャードに割り当てる際に、一貫性のあるハッシュ関数を使用してキーを生成し、そのキーに基づいてシャードを決定します。
シャード間でデータが均等に分散されるように設計することが重要です。
例えば、顧客IDの連番だけを基にシャーディングを行うと、アクセスパターンに偏りが生じやすくなります。この偏りは、特定のシャードに過剰な負荷がかかる原因となり、パフォーマンスの低下やスケーラビリティの問題を引き起こす可能性があります。
シャーディング戦略
ハッシュベースのシャーディング:
- 顧客IDなどのキーにハッシュ関数を適用し、その結果に基づいてシャードを決定する。ハッシュ関数は、データを均等に分散させるのに有効な手段ですが、レンジベースのクエリには適していないことがあります
範囲ベースのシャーディング:
- データを特定の範囲に基づいてシャードに割り当てます。この方法は、レンジベースのクエリに適していますが、データの成長パターンを考慮して均等な分散を維持することが重要です。
カスタムシャーディング戦略:
- アプリケーションの特定の要件に基づき、カスタムシャーディング戦略を考える。
トランザクション
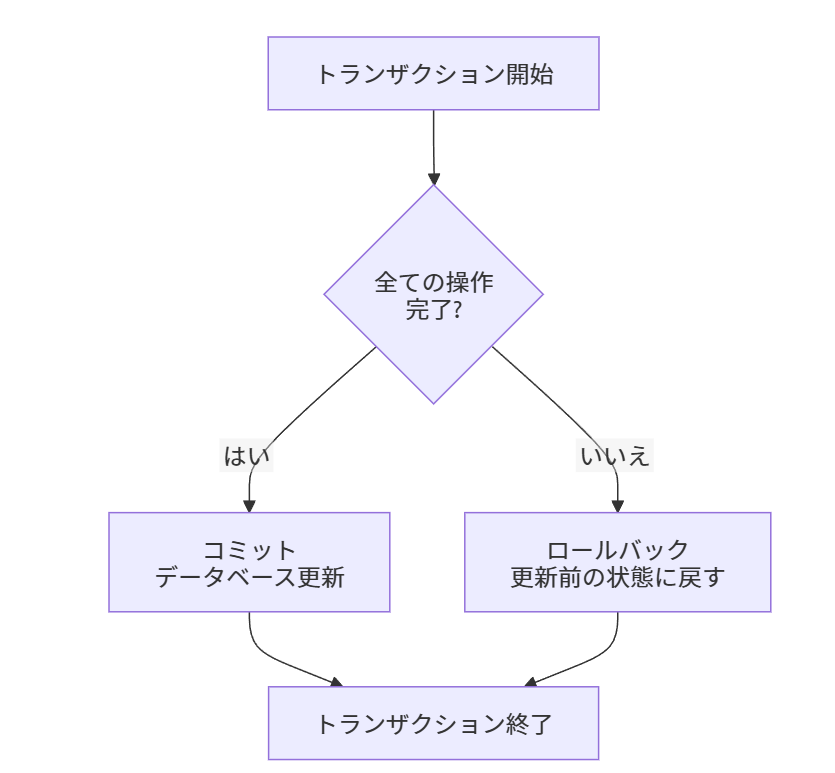
トランザクションは一連のデータベース操作(例えば、データの挿入、更新、削除)を一つの単位として扱います。
すべての操作が正常に完了すると、トランザクションは「コミット」され、データベースの状態が更新されます。もしトランザクション中に何か問題が発生し、すべての操作を正常に完了することができない場合、トランザクションは「ロールバック」され、データベースの状態はトランザクション開始前の状態に戻されます。
特徴
- 原子性 (Atomicity): トランザクション内の全操作は「全て実行されるか、全て実行されないか」のいずれかです。中途半端な状態で終了することはありません。
- 一貫性 (Consistency): トランザクションの実行前後でデータベースの整合性が保持されます。
- 隔離性 (Isolation): 複数のトランザクションが同時に実行される場合でも、各トランザクションは他のトランザクションの途中結果に影響されることなく独立して実行されます。
- 持続性 (Durability): トランザクションがコミットされると、その結果はシステム障害が発生しても失われることはありません。
注意点
- デッドロック: 複数のトランザクションが互いに必要とするリソースをロックし合うことで、進行が停止する現象。デッドロックを避けるためには、リソースのロック順序を一貫させる、タイムアウトを設定するなどの対策が必要です。
- 長時間のトランザクション: トランザクションが長時間にわたってロックを保持すると、他のトランザクションが待たされる原因となります。可能な限りトランザクションを小さく、短時間に保つことが推奨されます。
対策:
- リソースのロック順序の統一: リソースをアルファベット順や一定の順序でロックするようにプログラムを設計します。
- タイムアウトの設定: トランザクションがロックを獲得できない場合には、一定時間待った後、トランザクションを中断(タイムアウト)させます。
- ロックの粒度の調整:行レベルのロックを利用することで、テーブル全体をロックするよりも、競合の可能性を減らすことができます。
スロークエリの最適化
スロークエリは、データベースのパフォーマンス低下の主な原因の一つです。
スロークエリの分析と最適化により、データベースのレスポンス時間を短縮し、全体のパフォーマンスを向上させることができます。
スロークエリの具体例として、以下のようなものがあります。
具体例 1: インデックス未使用
SELECT * FROM customers WHERE email = '[email protected]';
このクエリは、email カラムにインデックスがないため、テーブル全体をスキャンする必要があり、パフォーマンスが大幅に低下します。
最適化: email カラムにインデックスを作成します。
CREATE INDEX idx_email ON customers(email);
具体例 2: 不要な全列選択
SELECT * FROM customers;
最適化: 必要な列のみを指定してクエリを実行します。
SELECT name, email FROM customers;
具体例 3: 複雑な結合操作
SELECT Orders.id, Customers.name, Orders.order_date
FROM Orders
INNER JOIN Customers ON Orders.customer_id = Customers.id
WHERE Customers.country = 'Japan';
最適化: 関連するテーブルに適切なインデックスを設定し、必要なら結合するテーブルの数を減らす。
また、結合の前にフィルタリングを行うことで、結合するレコードの数を減らすことができます。
具体例 4: 大量データの集計クエリ
SELECT AVG(price), MAX(price), MIN(price) FROM sales;
最適化: 集計を行う前にデータをフィルタリングして、分析対象のデータ量を減らします。
また、集計をより効率的に行うために、データベースの設定を最適化する。
スロークエリ最適化
クエリキャッシング:一部のデータベース管理システムでは、結果のキャッシングを利用して、同じクエリの結果を再利用することができます。頻繁に実行されるがデータがあまり変わらないクエリに対して特に有効です。
例:https://qiita.com/shota0616/items/68274bed508cb10e3355
正規化と非正規化のバランス:正規化はデータの整合性を保つために重要ですが、過度の正規化はクエリのパフォーマンスを低下させることがあります。
分割表やパーティショニング:大規模なテーブルを複数の物理的な部分に分割することで、クエリの実行速度を向上させることができます。パーティショニングを利用すると、特定のデータセグメントのみを対象にクエリを実行できるようになります。
ビューの使用:複雑なクエリの結果をビューとして保存し、それを単純なクエリでアクセスすることで、パフォーマンスを向上させることが可能です。
スロークエリの特定
- ログ分析: 多くのデータベース管理システムは、実行時間が長いクエリを記録するスロークエリログを提供します。このログを定期的に確認することで、パフォーマンスの問題を引き起こしているクエリを特定できます。
- 監視ツールの使用: 監視ツールを使用してデータベースのパフォーマンスをリアルタイムで監視し、スロークエリを即座に特定することができます。
補足:
Amazon RDSを使用している場合、Performance Inssightsというものがあります。
Performance Insights(RDSのパフォーマンスを分析、チューニング)| AWS
バッファプールとコネクションプーリング
バッファプールとコネクションプーリングは、データベースのパフォーマンスと効率を最適化するために重要な技術です。これらは異なる問題を解決するために設計されていますが、共にシステムの全体的な応答性とスループットを改善します。
バッファプール
データベース管理システムのメモリ内部に存在する一種のキャッシュです。
ディスクから読み込まれたデータやインデックスのページを保持し、同じデータへの後続のアクセスがあった場合に、高速にデータを提供できるようにします。
バッファプールを利用することで、ディスクI/Oの回数を減らし、データアクセスの速度を向上させることができます。
具体例:
MySQLデータベースサーバーにおいて、**innodb_buffer_pool_size** パラメータを調整することで、バッファプールのサイズを増減させることができます。
このパラメータをサーバーの物理メモリの約70%~80%に設定することが一般的な最適化のプラクティスとされています。
これにより、InnoDBテーブルのデータとインデックスを効果的にキャッシュして、クエリの応答時間を短縮します。
コネクションプーリング
アプリケーションとデータベースサーバー間のコネクションを効率的に管理するための技術です。
アプリケーションがデータベースに接続するたびに新しいコネクションを確立する代わりに、コネクションプールから既存のコネクションを再利用します。
これにより、コネクション確立のオーバーヘッドが削減され、リソースの利用が最適化されます。
モダンなデータベースソリューション:AWS AuroraとAmazon DynamoDB
アプリケーション開発では、データベースのパフォーマンスとスケーラビリティが重要な要素になります。AWSのAuroraとAmazon DynamoDBは、これらの要件を満たすモダンなデータベースソリューションを提供しています。
これらのサービスは、自動レプリケーション、シャーディング、トランザクションサポートなどの機能を統合し、開発者がデータベース管理にかける時間を削減し、アプリケーション開発に集中できるように設計されています。
AWS Aurora: MySQLとPostgreSQLのパワーアップ版
AWS Auroraは、MySQLおよびPostgreSQLと完全に互換性があるマネージドリレーショナルデータベースサービスです。
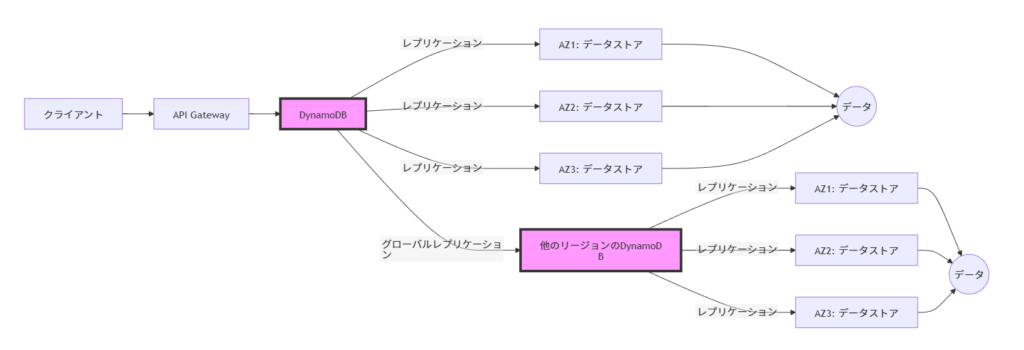
Auroraはこれらのオープンソースデータベースシステムよりも最大5倍高速かつ、自動化されたレプリケーションとフォールトトレランスの機能にあります。
Auroraは自動的にデータを複数のAZ(アベイラビリティゾーン)にレプリケートし、フェイルオーバーを秒単位で実行できます。
3つのアベイラビリティゾーンに6つのデータをコピーするので、耐障害性に優れている
補足:スナップショットとリストア
スナップショット・・・DBインスタンスのバックアップのこと
デフォルトで1日に1回、トランザクションログと一緒に取っている
最大35日間保存できる
リストア・・・スナップショットからDBインスタンスを作成すること
ポイントタイムリカバリで、自動バックアップを使って、5以上前の指定した時間の状態のDBインスタンスを作成する方法
使い分け
- 障害などの復旧 → ポイントタイムリカバリ
- 35日より前に戻したい場合は、手動でリストアする
リネーム
- エンドポイントの名前を変更できる
- そうすることでapplication側を変更しないで済む
Amazon DynamoDB: フルマネージドNoSQLデータベース
キーバリューおよびドキュメントデータモデルをサポートするフルマネージドのNoSQLデータベースサービスです。
DynamoDBは、ミリ秒単位のレイテンシで任意のスケールのトランザクション処理を提供します。
自動シャーディングとレプリケーションを通じて、グローバルなスケールでの高可用性と耐久性を保証します。
具体例:リアルタイムゲーミングプラットフォーム
オンラインゲームでは、世界中のプレイヤーからのリクエストをリアルタイムで処理する必要があります。DynamoDBは、これらのリアルタイムデータアクセス要件に対応するために設計されており、数百万のプレイヤーが同時にアクセスしても、安定したパフォーマンスを提供できます。
また、DynamoDB Streamsを使用すると、データ変更をリアルタイムでキャプチャし、他のAWSサービスと連携して迅速なデータ処理を行うことができます。
可用性を上げる仕組み
- グローバルテーブル: DynamoDBのグローバルテーブルを使用すると、データを複数のAWSリージョンに自動的にレプリケートできます。これにより、地理的な障害からデータを保護し、グローバルに分散されたユーザーへのレイテンシを最小限に抑えることができます。
- シャーディングとパーティショニング: DynamoDBはデータを自動的に複数のパーティションに分割し、均等に負荷を分散します。これにより、高いスループットと低レイテンシでのデータアクセスが可能になります。
まとめ
- ブラウザからのリクエスト: ユーザーがブラウザを介してECサイトにアクセスし、HTTP/HTTPSプロトコルを使用してリクエストを送信します。
- DNS解決: ブラウザはDNSを使用して、サイトのドメイン名をサーバーのIPアドレスに解決します。この過程でキャッシングが活用されることが多いです。
- CDNと地理的に最適なサーバーの選択: CDNを通じて、ユーザーに最も近いエッジサーバーが選択され、レスポンスタイムの最適化が図られます。
- セキュアな通信の確立: HTTPSプロトコルを介してTLS証明書を使用し、安全な通信チャネルを確立します。
- セキュリティ対策の適用: ファイアウォール、WAF、DDoS防御システムを介して、リクエストは様々なセキュリティ層を通過します。
- キャッシュ戦略の適用: 高頻度のリクエストに対しては、リバースプロキシサーバーやキャッシュサービスがキャッシュされたコンテンツを提供します。
- ロードバランシング: ALBまたはNLBを使用して入ってくるトラフィックを複数のアプリケーションサーバーに均等に分散します。
- アプリケーションサーバーでの処理: リクエストはアプリケーションサーバーで受け取られ、ビジネスロジックが実行されます。必要に応じて、データベースと通信が行われます。
- データベースとの通信: アプリケーションサーバーは、適切なプロトコルを使用してデータベースと通信し、データの取得や更新を行います。
- 高度なデータベース技術の活用: レプリケーション、シャーディング、トランザクションなどの技術を使用して、データベースのスケーラビリティ、可用性、整合性を保ちます。